透彻解析Redis中HyperLogLog的实现
潘忠显 / 2024-04-09
前文 中介绍了一下 HyperLogLog 的简单原理,并且强调了这种算法的神奇之处:内存使用量极低,计算复杂度低,而且可以支持多个数据集的并集操作,估算误差低。
本文带你透彻的看完 Redis 中的实现——redis 仓库中 hyperloglog.c,之后你就更会觉着神奇了。
至于有多“透彻”,笔者使用 Python 实现了与Redis完全一样的HLL。还顺便给 redis 仓库提了个 PR,优化了一下代码。
为了打消对阅读源码的畏惧,我这里列了一下 hyperloglog.c 的具体行数(总共只有 1600行左右,核心代码只有几百行):
- 原理描述的注释 300 行
- 位操作的宏定义 70 行
- 稠密表示处理 90 行
- 稀疏表示处理 370 行
- 核心 HyperLogLog 算法函数 260 行
- 命令处理函数 280 行
- 测试部分 220 行
接下来,我们开始来解析下代码。
一、理解存储结构
回顾下之前提到的:Redis 中,HyperLogLog 使用 64bit 的 Hash 函数,14bit 用于寄存器索引,剩下的 50bit 用于计算前导 0 的个数;Redis 中存储 HLL 本质使用的是字符串,可以通过 GET 获得其值。
struct hllhdr {
char magic[4]; /* "HYLL" */
uint8_t encoding; /* HLL_DENSE or HLL_SPARSE. */
uint8_t notused[3]; /* Reserved for future use, must be zero. */
uint8_t card[8]; /* Cached cardinality, little endian. */
uint8_t registers[]; /* Data bytes. */
};
1.1 头
通过上边的结构,我们可以看到整个 HLL 的结构有 4 个字段组成的“头”,以及寄存器数组地址。头中有三个有意义的元素:
+------+---+-----+----------+ | HYLL | E | N/U | Cardin. | +------+---+-----+----------+
- char magic[4]:魔字符串,固定为 HYLL
- encoding:1字节,标识是何种编码方式
- card: 8 字节,以小端序存储的 64 位整数,用于存储最近计算的基数(Cardinality)
细节1 - 字节序:最近是面试季,字节顺序是常见题目。正因为有超过1字节的整数,才需要字节序来定义哪个字节存储整数的哪一部分。能说出大小端序区别的应试者,并非都能理解其应用场景。card 以小端序存储,就是低地址的字节存储数字的低有效位。
细节2 - Cache有效位:card中有1 bit用来标识基数估算值是否有效,即其中的值是最新值的 Cache,还是过期的 Cache 值。这里后边4.4节会做详细介绍。
实际 Header 解析
我们来实际观察一个 HLL 的 Header:
127.0.0.1:6379> PFADD test_key user1
(integer) 1
127.0.0.1:6379> PFCOUNT test_key
(integer) 1
127.0.0.1:6379> GETRANGE test_key 0 15
"HYLL\x01\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00"
根据前面的介绍可以看到 magic = “HYLL”, encoding = 1 表示是稀疏模式,而 card = 0x01(忽略了高位的0x00),表示基数估算值为 1。
1.2 寄存器数组存储
前文中有介绍,HLL 使用了 14 位作为寄存器的索引,50位用于计算连续0的个数。因此寄存器有 2^14 => 16384个,而每个寄存器大小 6bit 可以记录 063(实际只会是 051)。
接下来我们看看实现中,register 的两种存储方式。其实稠密和稀疏描述的是寄存器的占用情况,如果16384 个寄存器中极少数有值而大部分是0就会使用稀疏模式,而大多数有值而极少数是0就会使用稠密模式
稠密模式
稠密模式是为每个寄存器都分配空间,存储的总大小是 6 * 16384 / 8 => 12KB。其在内存中具体的分布如下:
* The dense representation used by Redis is the following:
*
* +--------+--------+--------+------// //--+
* |11000000|22221111|33333322|55444444 .... |
* +--------+--------+--------+------// //--+
细节: 每个字节先使用最低有效位(即从右侧开始使用)。如果一个寄存器会落在两个字节中,则前边一个字节放的是寄存器的低有效位,比如上边第一字节的 11 是 register[1] 的最低两位。前三个字节中寄存器的实际取值的获得方法是:
r0 = r[0] & 63;
r1 = (r[0] >> 6 | r[1] << 2) & 63;
r2 = (r[1] >> 4 | r[2] << 4) & 63;
r3 = (r[2] >> 2) & 63;
稀疏模式
在只有少量寄存器有值的场景中,稀疏模式可以极大地压缩空间,这对内存型数据库的 Redis 来说,非常重要。我们来直观地感受一下,以前面只加入一个user1 的 test_key 来观察,总共长度是21,除去16字节头部,仅仅使用了5 字节来代替了 12KB 的存储空间。
127.0.0.1:6379> STRLEN test_key
(integer) 21
127.0.0.1:6379> GETRANGE test_key 16 20
"y\x00\x80F\xfd"
-- 0b01111001 0b00000000 0b10000000 0b01000110 0b11111101
稀疏模式的实现方式比较简单,学过《信息论》的都有做过类似的题目,其实就是将所有寄存器的值进行编码。
有三种编码操作符
- ZERO:00xxxxxx, 00 是前缀,6bit 表示连续0的长度
- XZERO:01xxxxxx yyyyyyyy,01是前缀,14bit 表示连续0的长度,最多可以表示 16384个
- VAL:1vvvvvxx,1是前缀,5bit 表示要设成的值,2bit 表示非 0 值的连续长度
XZERO 中的 X 是 eXtensible 的意思,表示对 ZERO 的扩展,可以处理更长。
根据上边的例子中的 5 个字节,我们可以解析成 3 条操作,即只有下标为 14593 的寄存器是 1:
XZERO: 14593 # 0b01111001 0b00000000
VAL: 1,1 # 0b10000000
XZERO: 1790 # 0b01000110 0b11111101
我这里也提供了工具,来将稀疏模式转换成可读的命令序列。
细节1:这里的长度、值的在存储的时候,都 -1 了,因为连续长度至少是1,设置的值最小也是1,进行 -1 可以存储更多信息。比如 VAL: 1,1 对应的 bit 是 00000 和 00。
细节2:VAL 能记录的最大值是 5 bit,也就是最大能记录 32,如果连续 0 的超过这个长度,就会转换成稠密模式。
模式切换
除了上边提到的大数值无法用稀疏模式表示,还要考虑什么情况从稀疏模式切换成稠密模式。
源代码中有给出稀疏模式表示的计数值和存储空间的一个关系,是个大概关系:
| 基数估计值 | 稀疏模式占用空间 |
|---|---|
| 100 | 267 |
| 500 | 1033 |
| 1000 | 1882 |
| 2000 | 3480 |
| 3000 | 4879 |
| 5000 | 7138 |
| 10000 | 10591 |
上边可以看到,在基数是10000左右的时候,稀疏模式占用的空间已经快接近稠密模式的 12KB 了。那是不是在这时候做切换呢?其实要更早,当稀疏模式所占空间接近稠密模式时,空间上的优势变得很小,但编码/解码将会带来计算量的增加,相对于稠密模式明显地增加了 CPU 的负担。因此要取得比较明显的优势,需要将这个转换门槛设置的更低。
when this implementation switches to the dense representation is configured via the define server.hll_sparse_max_bytes.
因此,配置项 hll_sparse_max_bytes 默认是 3000,也就是当稀疏表示的长度超过 3000 时,会转换成稠密模式。
1.3 低层次位操作的宏
可以根据源码中的一些宏定义,再理解一下 HLL 数据结构的设计。
宏定义
64 bit hash 分为两部分,HLL_P 决定使用哪个寄存器,HLL_Q 用于判断 连续开头 0 的个数。
#define HLL_P 14 /* The greater is P, the smaller the error. */
#define HLL_Q (64-HLL_P) /* The number of bits of the hash value used for
determining the number of leading zeros. */
因为 14 位用来决定寄存器,所以寄存器的个数就有 2^14 个,即 1«HLL_P 个:
#define HLL_REGISTERS (1<<HLL_P) /* With P=14, 16384 registers. */
#define HLL_P_MASK (HLL_REGISTERS-1) /* Mask to index register. */
#define HLL_BITS 6 /* Enough to count up to 63 leading zeroes. */
#define HLL_REGISTER_MAX ((1<<HLL_BITS)-1)
头长度和总长度:
#define HLL_HDR_SIZE sizeof(struct hllhdr)
#define HLL_DENSE_SIZE (HLL_HDR_SIZE+((HLL_REGISTERS*HLL_BITS+7)/8))
辅助位操作
为了便于理解,这里只介绍稠密模式的相关操作。
- HLL_DENSE_GET_REGISTER,获取指定寄存器的值
- HLL_DENSE_SET_REGISTER,设置指定寄存器的值
- HLL_INVALIDATE_CACHE,设置 Cache 失效标志
- HLL_VALID_CACHE,将 Cache 置为有效
二、HLL 算法辅助函数
接下来,开始介绍 HLL 的算法实现部分。
这里所谓“辅助”是相对于后边的“封装”函数一节而言的,但是 HLL 的核心思想也有体现在这些函数中。比如 Hash、000..1 的长度、加入一个新元素等等。
前边提到过,Redis 实现 HLL 是分为稠密和稀疏两种模式,两种只是存储方式的区别。因此,为了简洁清晰,这部分也只介绍稠密模式的相关函数。
2.1 Hash 函数
HyperLogLog 需要一个64位 Hash 函数,Redis 的实现中采用了 MurmurHash2 的 64 位版本。MurmurHash2 是一种非加密的哈希算法,具有良好的分布性和较低的冲突率,同时在处理速度和哈希质量之间做了平衡。
实现中进行了端序中立的修改——可以在大端和小端架构中提供相同的结果。
uint64_t MurmurHash64A (const void * key, int len, unsigned int seed)
const void * key, int len 用来表示需要做 Hash 的内容,是典型的 C 语言中表达方式。指针指向数据的起始位置,而长度表示数据的大小或长度。
unsigned int seed 用于初始化哈希算法的种子值,该函数实际被调用的时候,固定传入的是 0xadc83b19ULL。
2.2 hllPatLen
作用:将一个 字符串进行 Hash,获得 64bit Hash 值之后,计算:
- 对应寄存器索引(最低的 14bit)
- pattern 000..1 的长度(高 50bit),计数是从1开始的
这里有两个重要细节:
细节1:在计算 pattern 的时候,其实是从最低有效位往最高有效位去判断的,也就是计算最右侧 10..00 连续0的长度。为了简化处理,源码中直接将第 51 位设置成了1(hash |= ((uint64_t)1<<HLL_Q);)
细节2:计数是从 1 开始的,而不是从 0 开始,取值范围可能是 1HLL_Q。这样做的好处是,寄存器中的值如果是 0 表示还没有进来过元素。这也决定了,后边的 RegHisto 直方统计数组得有 HLL_Q + 2 个元素(0,1HLL_Q)。
2.3 hllDenseSet / hllDenseAdd
int hllDenseSet(uint8_t *registers, long index, uint8_t count)
作用:在给定的稠密 HLL 寄存器数组中,将指定索引的寄存器的值设置为 count 值,前提是当前值小于给定值。
这里我们再次加深一下印象:寄存器中存储的,是落到这个寄存器的所有值的最大 hllPatLen 的值。所以假设寄存器原来的值是 4,我们要设置进去一个 2,是不起作用的;只有设置进去一个比 4 大的才会起作用。
而只有当寄存器的值发生变化,计算的近似基数才会发生变化。所以这个函数通过返回 1/0,来表示寄存器是否发生变化,来进一步决定后边是否更新 “Cardin.” 中存储的近似基数。
hllDenseAdd 是对 hllPatLen + hllDenseSet 做了一个简单封装,可以直接通过传入内容,来更新寄存器。
2.4 hllDenseRegHisto
这个函数的作用是计算在密集表示中的寄存器直方图。两个入参分别是:
registers是包含所有寄存器的数组,总共有 16384 个 6 bits的寄存器reghisto是个数组,用来存储各寄存器的数值的频率;因为每个寄存器 6bit,取值0~63,所以 reghisto 的长度只有 64。但实际上寄存器中的值,只会存0HLL_Q(051),后边的一些bit一定会是0
编码技巧
看历史提交可以看到,这个函数有过较大的改动。之前是使用 通用的宏定义 来获得每个位置寄存器值,但是这样的效率比较低,每个都需要做很多运算得到对应的 6bit。
这次修改提交中,考虑到一个寄存器 6bit,4 个寄存器(24 bit, 3字节)一起处理,可以确切地知道 4 个寄存器需要通过第几个字节做几次移位来一次性得到结果。循环处理所有寄存器,之后每 3 字节/4 个寄存器就可以使用相同的代码逻辑处理。
同时,因为 r0、r1、r2、r3 的值的获取相互不会依赖,可以在构建时使用优化选项,利用 CPU 的特性乱序并发执行,可以提高其执行速度。
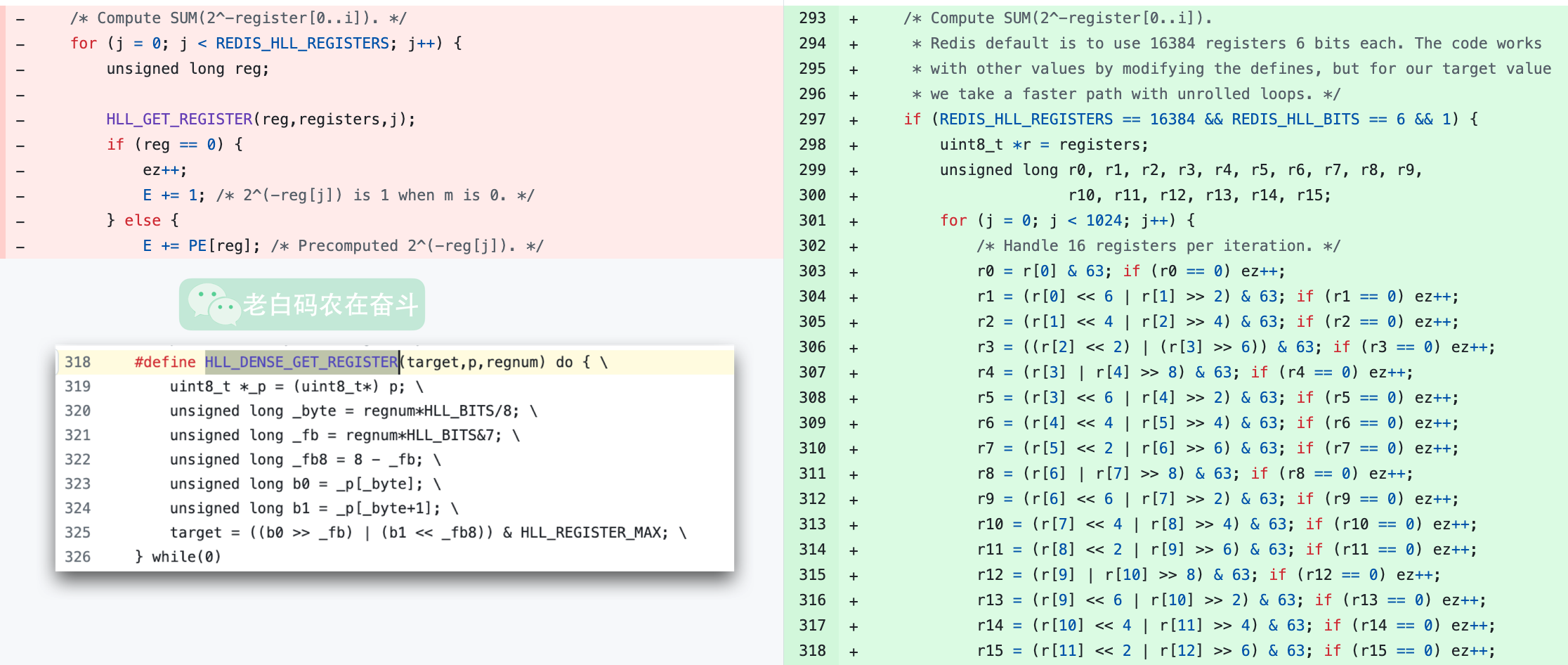
注释中提到了 unrolled loops,看上去是单纯的将 4次循环展成 1 次即可——一次处理 3 字节,那为什么源码中使用的是 12 字节呢? (可以看到后边3个红框中的逻辑,实际是重复第一个红框):

难道的多展开几次真的效率更高? 带着这些疑问,我写了一个简单测试使用 GCC -O3 flag 去构建,发现一个循环处理 3 字节要比处理 12 字节更快。具体的可以看这里。因此,顺手提了个 Pull Request 给 Redis。
三、HLL 算法封装函数
注释中介绍这些函数是 “core of the algorithm where the approximated count is computed”,我们依然只关注 稠密模式的处理逻辑。
3.1 hllCount
这个函数实际估算基数值。其实现是使用了 《New cardinality estimation algorithms for HyperLogLog sketches》 一文中的算法 6:

算法中涉及到三个系数:
- hllSigma(),函数
- hllTau(),函数
HLL_ALPHA_INF,宏定义
编程技巧
前边反复提到,每个寄存器中的值逻辑上最大应该是 51。
在 hllCount 函数中调用 hllDenseRegHisto 之前,需要创建一个直方图的数组。这里直接分配了一个 int[64] 的数组。
因为这里考虑到寄存器虽然逻辑上最大是 51,但实际其是用 6bit 进行存储,如果 Redis 中数据有异常,是可能得到大于 51 的数值的。
为了避免因为数据异常而造成数组越界,可以:
- 增加判断寄存器中的值,直方图只统计合理值
- 将直方图的统计范围拉到 64,可以涵盖所有 6bit 的表示值
选择后者的原因:可以减少判断,让代码更简洁,而使用额外的部分承载溢出的数据,带来不了多少负担。
3.2 hllAdd
对前面提到的 hllDenseAdd 等函数的简单封装,针对不同的 encoding 调用不同的 add 函数。
3.3 llMerge
比较有意思的,两个 HLL 可以合并。结合我们最初介绍的扔硬币的场景,这个合并也比较好理解,就是两个HLL的每个对应编号的两个寄存器,取其最大值即可。
该函数是内部函数,其参数有两个,前者 max 对应一个寄存器的 HLL_RAW 形式。后者 hll 是个 Redis 对象 robj 的指针。函数会将后边的 hll 的 merge 到前边的 max 计数数组中。
四、Redis命令相关函数
4.1 两个辅助函数
以下两个函数不会被 Redis 命令直接调用,但是会在 HLL 相关指令调用时,被间接用到:
- createHLLObject:创建 HLL 对象,因为是个新的空对象,所以是直接创建一个稀疏模式的对象。
- isHLLObjectOrReply: 判断对象是否是 HLL 对象
4.2 pfaddCommand
/* PFADD var ele ele ele … ele => :0 or :1 */
- 检查对象,如不存在则创建,如果存在且非 HLL 对象报错退出
- 针对key,对每个要加入的元素调用
hllAdd,记录更新的次数 - 如果存在更新,将基数 cache 位设置为无效
4.3 pfcountCommand
PFCOUNT 支持传入多个key,其作用是计算这多个 key 合并后的基数。因此,单个 key 和多个 key 的逻辑处理不一样。
单个 key 的处理,同样先进行常规的检查。然后计算计数:
- 如果 cache 有效,直接返回 cached 基数
- 如果 cache 失效(由于上边 pfadd 导致的),需要重新计算基数并 cache,返回
4.4 Cache 的设计
因为基数估算值是根据后边的所有寄存器计算出来的,只寄存器中的值没有发生变化,这个值就不会变,可以直接使用上次计算的结果。
基于此,Redis 的实现中,HLL Header 中的 uint8_t card[8] 实际是个 Cache 值,而其中有一位就是用来标记 Cache 是否失效的(card[7] 的最高位):
#define HLL_VALID_CACHE(hdr) (((hdr)->card[7] & (1<<7)) == 0)
而当调用 PFADD 并且导致寄存器更新的时候,这个有效位会被置成无效,直到下次 PFCOUNT 时,判断需要重新计算,并将有效位置成有效。
该逻辑我们也可以通过 redis-cli 的指令清晰的观察到:
- 调用 PFADD 向空的 HLL 中加入一个元素之后,可以看到 card[7] 的值是 0x80,也就是 0b1000000,此时的估算值cache 是0,但是失效位是1,表示已经失效
- 调用一次 PFCOUNT 之后,card 变成了 1,而最高位变成了0,表示这里边的1是有效的基数估计值的Cache
127.0.0.1:6379> PFADD test_key user1
(integer) 1
127.0.0.1:6379> GETRANGE test_key 8 15
"\x00\x00\x00\x00\x00\x00\x00\x80"
127.0.0.1:6379> PFCOUNT test_key
(integer) 1
127.0.0.1:6379> GETRANGE test_key 8 15
"\x01\x00\x00\x00\x00\x00\x00\x00"
通过重复使用之前计算的基数值,可以节省计算时间和资源,并在实际数据结构没有修改的情况下提供近似的基数估计。这对于需要频繁进行基数估计、频繁进行新值插入的场景都非常有用:
PFADD远多于PFCOUNT,在每次PFADD之后,只是简单的将 chach 标志置为失效,不需要计算PFCOUNT远多于PFADD,在绝大部分PFCOUNT都是直接读取的缓存值,而无需计算
4.5 pfmergeCommand
/* PFMERGE dest src1 src2 src3 … srcN => OK */
首先创建一个数组,用来存储合并之后的16324 个寄存器的计数值。
然后处理每一个 HLL,调用 hllMerge 计算每个索引寄存器的最大值。
最后将合并之后的寄存器数组转换成 HLL 对象,存储到 dest。
4.6 Redis 存储的相关函数
在以上三个函数中,我们都能看到,如果 HLL 对象发生变化,都会调用一段类似于这样的代码:
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_STRING,"pfadd",c->argv[1],c->db->id);
server.dirty += updated;
其中,c->db 是数据库的引用,c->db->id 是对应数据库的 ID。
这三个函数在Redis中的作用如下:
signalModifiedKey(c,c->db,c->argv[1]):用于通知 Redis 系统,一个键(c->argv[1])已经被修改了。这是Redis内部用于维护数据一致性的一种机制。notifyKeyspaceEvent(NOTIFY_STRING,"pfadd",c->argv[1],c->db->id):用于触发一个键空间事件,通知所有订阅了这个事件的客户端。在这个例子中,事件类型是NOTIFY_STRING,事件名称是pfadd,关联的键是c->argv[1]。server.dirty++;:这个语句用于增加服务器的 dirty 寄存器。在Redis中,该寄存器用于跟踪自上次保存以来数据库被修改的次数。每当一个写命令成功执行,这个寄存器就会增加。这个寄存器用于决定何时触发自动保存(AOF 或 RDB)。
另外,还有两个在函数进入时可能会调用的指令:
robj *o = lookupKeyWrite(c->db,c->argv[1]);
robj *o = lookupKeyRead(c->db,c->argv[j]);
这两个函数用于在数据库中查找一个键,并准备对它进行写/读操作。如果键存在,它返回一个指向该键的对象的指针。如果键不存在,它返回NULL。
两个函数的主要区别在于:lookupKeyWrite 会对键进行写入前的准备(例如,如果键被设置为只读,该函数会返回错误),而 lookupKeyRead 则不会。
五、自行实现HLL
至此,看上去我已经理解了 Redis 中 HyperLogLog 的实现。如何验证我理解的对不对以及全不全呢?
纸上得来终觉浅,觉知此事需躬行。既然这实现这么简单,我就自己使用 Python 重新实现一遍吧。实际实现出来代码只有 140 行,详见这里。
如何验证实现是正确的呢?分别往 Redis 中的一个key 和自己实现的 HLL 中插入 10万个元素:
- 比较 Redis 中寄存器的数组和自行实现的HLL中数值是完全一致,说明对 MurmurHash64A、取寄存器下标、计算 00..01 长度都是正确的
- 比较 Redis PFCOUNT 和 自行实现 HLL 的结果,两个完全一致,说明对 hllTau、hllSigma、hllCount 等函数的理解都是正确的
tools.py 中还提供了一些工具函数:
dump_header():解析 Redis 中 HLL Headerparse_sparse_registers():将稀疏模式的数据,转换成 XZERO/ZERO/VAL 的操作parse_dense_registers():将稠密模式的数据,解析成register数组
总结
本文把 redis 的 hyperloglog.c 给详细的解析了一遍,并且根据理解自行实现了一个 HyperLogLog。
再次感受到了算法的神奇,希望你也能感受到这种神奇,并让这神奇带给你愉悦。